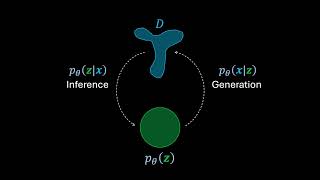
The Vector-Quantized Variational Autoencoder (VQ-VAE) forms discrete latent representations, by mapping encoding vectors to a limited size codebook. But, how does it do this, and why would we want to do it anyway?
Link to my video on VAEs:
https://www.youtube.com/watch?v=HBYQvKlaE0A&t=963s
Timestamps
-------------------
00:00 Introduction
01:09 VAE refresher
02:42 Quantization
04:46 Posterior
06:09 Prior
07:06 Learned prior for sampling
09:55 Reconstruction loss
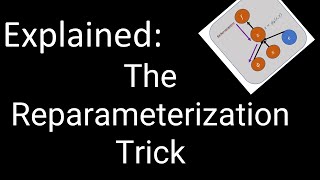
10:32 Straight-through estimation
11:50 Codebook loss
12:53 Commitment loss
14:33 Benefits of quantization
16:58 Application examples
Links
---------
- VQ-VAE paper: https://arxiv.org/abs/1711.00937
- Straight-through estimation paper: https://arxiv.org/abs/1308.3432
- PixelCNN paper: https://arxiv.org/abs/1606.05328
- WaveNet paper: https://arxiv.org/abs/1609.03499
- Text-to-Image paper: https://arxiv.org/abs/2111.14822
- Jukebox paper: https://arxiv.org/abs/2005.00341
- PyTorch implementation: https://github.com/airalcorn2/vqvae-pytorch
- Keras implementation: https://keras.io/examples/generative/vq_vae/

 13:15
13:15
 29:54
29:54
 1:40:09
1:40:09
 17:09
17:09
 24:04
24:04
 18:58
18:58
 18:54
18:54
 34:38
34:38
 13:53
13:53
 17:04
17:04
 38:11
38:11
 41:08
41:08
 20:18
20:18
 26:46
26:46
 15:17
15:17
 15:52
15:52
 17:35
17:35
 15:05
15:05
 1:52:36
1:52:36
 17:58
17:58





