Here, we run down how RNNs are trained via backpropagation through time, and see how this algorithm is plagued by the problems of vanishing and exploding gradients. We present an intuitive and mathematical picture by flying through the relevant calculus and linear algebra (so feel free to pause at certain bits!)
Timestamps
--------------------
00:00 Introduction
00:46 RNN refresher
03:42 Gradient calculation of W
06:50 Exploding and vanishing gradients
07:35 Linear algebra perspective
12:20 Solutions
Links
---------
- Papers on vanishing and exploding gradients
https://www.bioinf.jku.at/publications/older/2304.pdf
https://ieeexplore.ieee.org/document/279181
https://arxiv.org/abs/1211.5063
- Long short-term memory paper: https://www.bioinf.jku.at/publications/older/2604.pdf
- RNN paper (Elman networks): https://onlinelibrary.wiley.com/doi/10.1207/s15516709cog1402_1

 26:46
26:46
 25:28
25:28
 14:30
14:30
 1:13:50
1:13:50
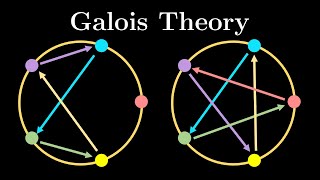 45:24
45:24
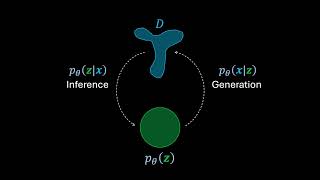 29:54
29:54
 19:34
19:34
 18:14
18:14
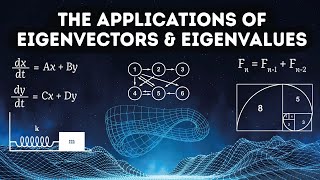 23:45
23:45
 18:54
18:54
 31:51
31:51
 36:54
36:54
 23:01
23:01
 10:06
10:06
 15:52
15:52
 18:58
18:58
 17:40
17:40
 19:44
19:44
 27:25
27:25
 12:06
12:06





