Can a ConvNet outperform a Vision Transformer? What kind of modifications do we have to apply to a ConvNet to make it as powerful as a Transformer? Spoiler: it’s not attention.
► SPONSOR: Weights & Biases 👉 https://wandb.me/ai-coffee-break
The official ConvNeXt repo has a W&B integration! Also, W&B built the CIFAR10 training colab linked there: 🥳 https://twitter.com/weights_biases/status/1486325233711828996
❓ Check out our daily #MachineLearning Quiz Questions: https://www.youtube.com/c/AICoffeeBreak/community
➡️ AI Coffee Break Merch! 🛍️ https://aicoffeebreak.creator-spring.com/
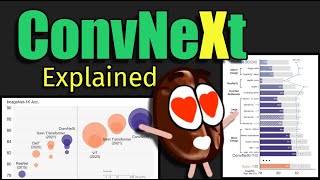
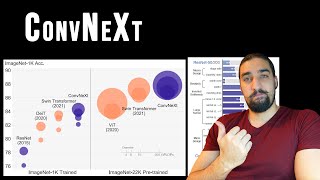
Explained Paper 📜: Liu, Zhuang, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, and Saining Xie. “A ConvNet for the 2020s.” arXiv preprint arXiv:2201.03545 (2022). https://arxiv.org/abs/2201.03545
🔗 Tweet of Lukas Beyer (ViT author): https://twitter.com/giffmana/status/1481054929573888005
🔗 Depthwise convolutions image and explanation: https://eli.thegreenplace.net/2018/depthwise-separable-convolutions-for-machine-learning/
Referenced videos:
📺 An image is worth 16x16 words:
https://youtu.be/DVoHvmww2lQ
📺 Swin Transformer:
https://youtu.be/SndHALawoag
📺 This is how Transformers can process both image and text:
https://youtu.be/aH7s6qXEUcc
📺 ViLBERT explained:
https://youtu.be/dd7nE4nbxN0
📺 DeiT explained:
https://youtu.be/-FbV2KgRM8A
📺 Transformers sequence length:
https://youtu.be/Xxts1ithupI
Referenced papers:
📜 “Image Transformer” Paper: Parmar, Niki, Ashish Vaswani, Jakob Uszkoreit, Lukasz Kaiser, Noam Shazeer, Alexander Ku, and Dustin Tran. “Image transformer.” In International Conference on Machine Learning, pp. 4055-4064. PMLR, 2018. https://arxiv.org/abs/1802.05751
📜 “ViLBERT“ paper: Lu, Jiasen, Dhruv Batra, Devi Parikh, and Stefan Lee. “Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks.” arXiv preprint arXiv:1908.02265 (2019). https://arxiv.org/abs/1908.02265
Outline:
00:00 A ConvNet for the 2020s
01:58 Weights & Biases (Sponsor)
03:10 Why bother?
04:40 The perks of ConvNets (CNNs)
06:51 Pros and cons of Transformers
09:54 From ConvNets to ConvNeXts
15:54 Lessons?
Thanks to our Patrons who support us in Tier 2, 3, 4: 🙏
donor, Dres. Trost GbR, banana.dev
▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀
🔥 Optionally, pay us a coffee to help with our Coffee Bean production! ☕
Patreon: https://www.patreon.com/AICoffeeBreak
Ko-fi: https://ko-fi.com/aicoffeebreak
▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀
🔗 Links:
AICoffeeBreakQuiz: https://www.youtube.com/c/AICoffeeBreak/community
Twitter: https://twitter.com/AICoffeeBreak
Reddit: https://www.reddit.com/r/AICoffeeBreak/
YouTube: https://www.youtube.com/AICoffeeBreak
#AICoffeeBreak #MsCoffeeBean #MachineLearning #AI #research
 19:15
19:15
 40:08
40:08
 23:01
23:01
 21:38
21:38
 12:56
12:56
 1:31:09
1:31:09
 58:04
58:04
 1:09:00
1:09:00
 29:56
29:56
 11:10
11:10
 20:18
20:18
 25:36:58
25:36:58
 26:10
26:10
 21:00
21:00
 39:13
39:13
 14:48
14:48
 10:54
10:54
 14:28
14:28
 24:23
24:23
 30:49
30:49





