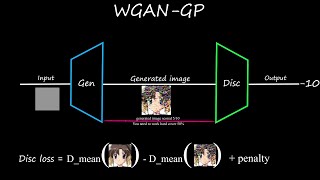
In this video, we'll explore the Wasserstein GAN with Gradient Penalty, which addresses the instability issues in traditional GANs. Unlike traditional GANs, WGANs use the Wasserstein distance as their loss function to measure the difference between the real and generated data distributions. The Gradient penalty is used to ensure that the gradients from the discriminator don't explode or vanish. We'll implement the WGAN with Gradient Penalty from scratch and use the anime faces dataset for training. Watch the video to learn how to create this type of GAN and improve its performance.
Link to dataset: https://rb.gy/iyolm
Link to code: https://github.com/henry32144/wgan-gp-tensorflow/blob/master/WGAN-GP-celeb64.ipynb
Instagram: https://www.instagram.com/developershutt/
And as always,
Thanks for watching ❤️
Chapters:
0:00 Intro
0:34 Wasserstein distance
1:15 Wasserstein as loss function
2:43 Gradient Penalty (Lipschitz continuity)
4:38 Code from scratch
11:45 Things to remember
 25:59
25:59
 26:46
26:46
 39:51
39:51
 23:20
23:20
 18:46
18:46
 26:42
26:42
 17:04
17:04
 26:44
26:44
 12:03
12:03
 18:08
18:08
 8:23
8:23
 11:43
11:43
 27:31
27:31
 2:01:24
2:01:24
 15:05
15:05
 7:23
7:23
 21:01
21:01
 23:44
23:44
 7:58
7:58
![[Classic] Generative Adversarial Networks (Paper Explained)](https://i.ytimg.com/vi/eyxmSmjmNS0/mqdefault.jpg) 37:04
37:04





