Vectorized Query Execution in Apache Spark at Facebook Chen Yang Facebook
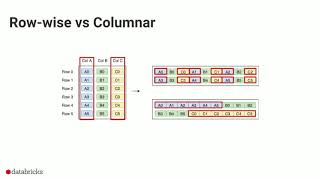
A standard query execution system processes one row at a time. Vectorized query execution batches multiples rows together in a columnar format, and each operator uses simple loops to iterate over data within a batch. This feature greatly reduces the CPU usage for reading, writing and query operations like scanning, filtering. In this talk, we will take a deep dive into Facebook's ORC-based vectorized reader and writer implementation, discuss how vectorization affects performance of various data types in Hive/Spark, and quantify the improvements vectorization brings to the Facebook Warehouse. About: Databricks provides a unified data analytics platform, powered by Apache Spark™, that accelerates innovation by unifying data science, engineering and business.
Read more here: https://databricks.com/product/unified-data-analytics-platform
Connect with us:
Website: https://databricks.com
Facebook: https://www.facebook.com/databricksinc
Twitter: https://twitter.com/databricks
LinkedIn: https://www.linkedin.com/company/databricks
Instagram: https://www.instagram.com/databricksinc/ Databricks is proud to announce that Gartner has named us a Leader in both the 2021 Magic Quadrant for Cloud Database Management Systems and the 2021 Magic Quadrant for Data Science and Machine Learning Platforms. Download the reports here. https://databricks.com/databricks-named-leader-by-gartner

 1:30:18
1:30:18
 6:12
6:12
 40:46
40:46
 28:09
28:09
 48:13
48:13
 31:19
31:19
 2:15:52
2:15:52
 1:02:44
1:02:44
 44:03
44:03
 1:05:38
1:05:38
 29:29
29:29
 1:15:10
1:15:10
 39:32
39:32
 39:19
39:19
 55:48
55:48
 1:15:44
1:15:44
 26:13
26:13
 24:47
24:47
 21:27
21:27
 29:50
29:50





