ABOUT ME
⭕ Subscribe: https://www.youtube.com/c/CodeEmporium?sub_confirmation=1
📚 Medium Blog: https://medium.com/@dataemporium
💻 Github: https://github.com/ajhalthor
👔 LinkedIn: https://www.linkedin.com/in/ajay-halthor-477974bb/
RESOURCES
[ 1 🔎] Code for Video: https://github.com/ajhalthor/Transformer-Neural-Network/blob/main/Transformer_Encoder_EXPLAINED!.ipynb
PLAYLISTS FROM MY CHANNEL
⭕ Transformers from scratch playlist:
https://www.youtube.com/watch?v=QCJQG4DuHT0&list=PLTl9hO2Oobd97qfWC40gOSU8C0iu0m2l4
⭕ ChatGPT Playlist of all other videos: https://youtube.com/playlist?list=PLTl9hO2Oobd9coYT6XsTraTBo4pL1j4HJ
⭕ Transformer Neural Networks: https://youtube.com/playlist?list=PLTl9hO2Oobd_bzXUpzKMKA3liq2kj6LfE
⭕ Convolutional Neural Networks: https://youtube.com/playlist?list=PLTl9hO2Oobd9U0XHz62Lw6EgIMkQpfz74
⭕ The Math You Should Know : https://youtube.com/playlist?list=PLTl9hO2Oobd-_5sGLnbgE8Poer1Xjzz4h
⭕ Probability Theory for Machine Learning: https://youtube.com/playlist?list=PLTl9hO2Oobd9bPcq0fj91Jgk_-h1H_W3V
⭕ Coding Machine Learning: https://youtube.com/playlist?list=PLTl9hO2Oobd82vcsOnvCNzxrZOlrz3RiD
MATH COURSES (7 day free trial)
📕 Mathematics for Machine Learning: https://imp.i384100.net/MathML
📕 Calculus: https://imp.i384100.net/Calculus
📕 Statistics for Data Science: https://imp.i384100.net/AdvancedStatistics
📕 Bayesian Statistics: https://imp.i384100.net/BayesianStatistics
📕 Linear Algebra: https://imp.i384100.net/LinearAlgebra
📕 Probability: https://imp.i384100.net/Probability
OTHER RELATED COURSES (7 day free trial)
📕 ⭐ Deep Learning Specialization: https://imp.i384100.net/Deep-Learning
📕 Python for Everybody: https://imp.i384100.net/python
📕 MLOps Course: https://imp.i384100.net/MLOps
📕 Natural Language Processing (NLP): https://imp.i384100.net/NLP
📕 Machine Learning in Production: https://imp.i384100.net/MLProduction
📕 Data Science Specialization: https://imp.i384100.net/DataScience
📕 Tensorflow: https://imp.i384100.net/Tensorflow
TIMESTAMP
0:00 What we will cover
0:53 Introducing Colab
1:24 Word Embeddings and d_model
3:00 What are Attention heads?
3:59 What is Dropout?
4:59 Why batch data?
7:46 How to sentences into the transformer?
9:03 Why feed forward layers in transformer?
9:44 Why Repeating Encoder layers?
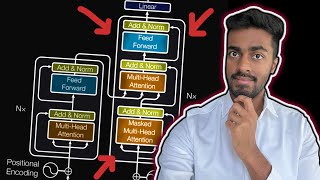
11:00 The “Encoder” Class, nn.Module, nn.Sequential
14:38 The “EncoderLayer” Class
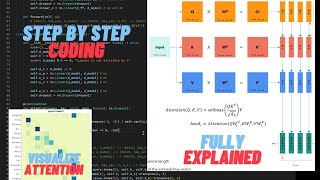
17:45 What is Attention: Query, Key, Value vectors
20:03 What is Attention: Matrix Transpose in PyTorch
21:17 What is Attention: Scaling
23:09 What is Attention: Masking
24:53 What is Attention: Softmax
25:42 What is Attention: Value Tensors
26:22 CRUX OF VIDEO: “MultiHeadAttention” Class
36:27 Returning the flow back to “EncoderLayer” Class
37:12 Layer Normalization
43:17 Returning the flow back to “EncoderLayer” Class
43:44 Feed Forward Layers
44:24 Why Activation Functions?
46:03 Finish the Flow of Encoder
48:03 Conclusion & Decoder for next video

 25:59
25:59
 26:56
26:56
 22:43
22:43
 20:58
20:58
 26:10
26:10
 16:27
16:27
 56:10
56:10
 29:22
29:22
 19:34
19:34
 57:45
57:45
 38:32
38:32
 27:53
27:53
 27:14
27:14
 1:56:20
1:56:20
 2:59:24
2:59:24
 13:34
13:34
 15:59
15:59
 1:22:38
1:22:38
 28:00
28:00
 39:54
39:54





