This video talks about SWIN transformer - a model trained for image classification, but also used in a variety of tasks as a backbone, replacing ResNet/ViT. It is currently the main part of SOTA object detection models like DINO.
This is another video from my "Modern Object Detection" series: https://www.youtube.com/playlist?list=PL1HdfW5-F8AQlPZCJBq2gNjERTDEAl8v3
Important links:
- Original paper: https://arxiv.org/pdf/2103.14030.pdf
- My previous video about ViT:
https://youtu.be/NcbbPuRjMeE
00:00 - Intro
00:50 - Motivation, "Image Tokenization" Problem
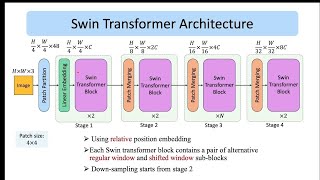
08:14 - Hierarchical Patches Architecture
10:40 - Shifted Windows Attention
17:26 - Relative Positional Bias
21:58 - Results
26:00 - Next Up

 28:59
28:59
 4:37
4:37
 11:10
11:10
 29:56
29:56
 27:14
27:14
 19:59
19:59
 17:50
17:50
 41:33
41:33
 30:49
30:49
 41:13
41:13
 16:51
16:51
 39:27
39:27
 35:44
35:44
 40:57
40:57
 1:15:50
1:15:50
 12:06
12:06
 26:10
26:10
 41:40
41:40





