At Splunk we have built a Flink streaming infrastructure and scaled it to petabytes of data per day and millions of events per second. Along the way, we've learned a lot about writing performant operations in the DataStream API and putting together high-throughput pipelines. This talk will cover our real-life experiences in scaling for this throughput and the best practices we've learned along the way. We'll talk about aggregation, built-in functions, user-defined functions, the async I/O API, as well as discoveries around GC, Java object management, state backends, and serialization.
0:00 Introduction
1.07 Environmental & Performance Testing
3:57 The basic challenges
10:17 Sources
21:22 Sinks
25:10 Putting it all together
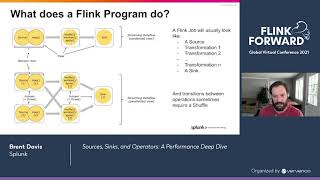
 26:35
26:35
 28:08
28:08
 35:12
35:12
 19:19
19:19
 11:58
11:58
 32:18
32:18
 34:03
34:03
 1:04:27
1:04:27
 13:51
13:51
 9:43
9:43
 12:05
12:05
 31:20
31:20
 1:04:42
1:04:42
 30:06
30:06
 42:54
42:54
 41:36
41:36
 1:21:09
1:21:09
 32:24
32:24
 7:50
7:50
 12:55
12:55





