
 14:16
14:16
 27:10
27:10
 1:23:07
1:23:07
 38:02
38:02
 1:19:14
1:19:14
 22:59
22:59
 21:37
21:37
 43:18
43:18
 9:48
9:48
 12:47
12:47
 17:42
17:42
 23:01
23:01
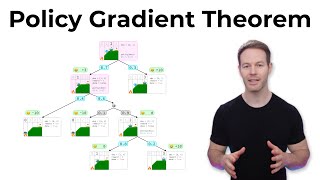 59:36
59:36
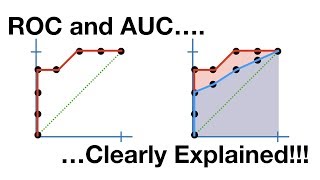 16:17
16:17
 1:25:00
1:25:00
 15:32
15:32
 20:05
20:05
 21:33
21:33
 36:26
36:26





