Observability for Data Pipelines With OpenLineage
Data is increasingly becoming core to many products. Whether to provide recommendations for users, getting insights on how they use the product, or using machine learning to improve the experience. This creates a critical need for reliable data operations and understanding how data is flowing through our systems. Data pipelines must be auditable, reliable, and run on time. This proves particularly difficult in a constantly changing, fast-paced environment.
Collecting this lineage metadata as data pipelines are running provides an understanding of dependencies between many teams consuming and producing data and how constant changes impact them. It is the underlying foundation that enables the many use cases related to data operations. The OpenLineage project is an API standardizing this metadata across the ecosystem, reducing complexity and duplicate work in collecting lineage information. It enables many projects, consumers of lineage in the ecosystem whether they focus on operations, governance or security.
Marquez is an open source project part of the LF AI & Data foundation which instruments data pipelines to collect lineage and metadata and enable those use cases. It implements the OpenLineage API and provides context by making visible dependencies across organizations and technologies as they change over time.
Connect with us:
Website: https://databricks.com
Facebook: https://www.facebook.com/databricksinc
Twitter: https://twitter.com/databricks
LinkedIn: https://www.linkedin.com/company/databricks
Instagram: https://www.instagram.com/databricksinc/ Databricks is proud to announce that Gartner has named us a Leader in both the 2021 Magic Quadrant for Cloud Database Management Systems and the 2021 Magic Quadrant for Data Science and Machine Learning Platforms. Download the reports here. https://databricks.com/databricks-named-leader-by-gartner

 27:14
27:14
 28:32
28:32
 27:43
27:43
 27:47
27:47
 23:44
23:44
 50:44
50:44
 1:03:12
1:03:12
 12:05
12:05
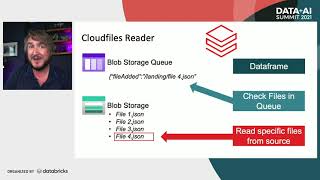 59:25
59:25
 18:05
18:05
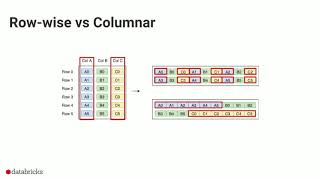 40:46
40:46
 27:47
27:47
 19:28
19:28
 12:02
12:02
 11:30
11:30
 58:10
58:10
 14:49
14:49
 39:52
39:52
 36:25
36:25
 38:08
38:08





