
 19:36
19:36
 2:50:14
2:50:14
 21:27
21:27
 24:06
24:06
 25:26
25:26
 4:28:44
4:28:44
 22:23
22:23
 8:27
8:27
 25:36:58
25:36:58
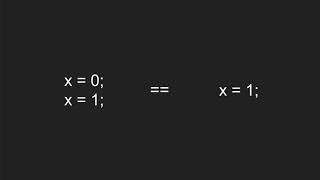 1:12:34
1:12:34
 36:54
36:54
 14:40
14:40
 53:25
53:25
 21:20
21:20
 18:13
18:13
 1:00:49
1:00:49
 3:21:34
3:21:34
 13:27
13:27
 29:38
29:38





