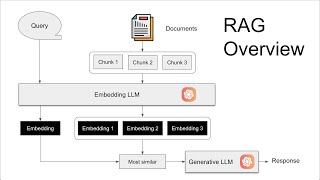
Hey everyone! Thank you so much for watching this explanation of "Lost in the Middle: How Language Models use Long Context" from Liu et al. 2023! This paper has really interesting findings with regards to the impact of search quality on the resulting generation ability in RAG (Retrieval-Augmented Generation) stacks! The authors find this u-shaped curve that shows the LLM is unable to correctly answer questions when the relevant information is in the middle of the search results! This video will dive into all the experimental details, I hope you find it useful! As always, we are more than happy to answer any questions or discuss any ideas you have about the content!
Paper Link: https://arxiv.org/pdf/2307.03172.pdf
AutoCut in Weaviate: https://weaviate.io/developers/weaviate/search/similarity#autocut
Re-Rankers in Weaviate!
Re-Ranker Cohere: https://weaviate.io/developers/weaviate/modules/retriever-vectorizer-modules/reranker-cohere
Re-Ranker Transformers: https://weaviate.io/developers/weaviate/modules/retriever-vectorizer-modules/reranker-transformers
Hybrid Search in Weaviate: https://weaviate.io/developers/weaviate/search/hybrid
Chapters
0:00 Introduction
1:18 RAG - Quick Background
3:01 Key Controls and Finding
4:05 Multi-Document QA Experiment
9:20 More Realistic Test
11:07 Key-Value Retrieval
13:13 Further Investigations
17:00 My Takeaways and New Weaviate Search Features

 33:25
33:25
 1:50:09
1:50:09
 14:14
14:14
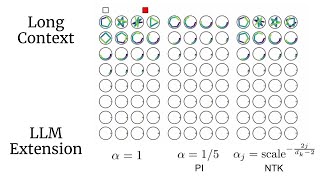 25:45
25:45
 37:17
37:17
 59:33
59:33
 1:18:42
1:18:42
 19:49
19:49
![Niebezpieczne związki Rafała Trzaskowskiego. Wojciech Sumliński [Expert w Bentleyu]](https://i.ytimg.com/vi/4WFj252Jbrc/mqdefault.jpg) 1:33:33
1:33:33
 1:19:27
1:19:27
 9:38
9:38
 19:15
19:15
 27:14
27:14
 18:38
18:38
 37:21
37:21
 21:08
21:08
 12:21
12:21
 34:31
34:31
 14:01
14:01
 29:17
29:17





