#llm #embedding #gpt
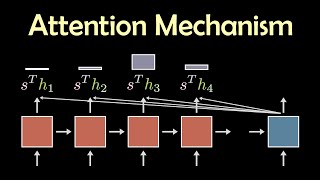
The attention mechanism in transformers is a key component that allows models to focus on different parts of an input sequence when making predictions. Attention assigns varying degrees of importance to different parts of the input, enabling the model to capture contextual relationships effectively. The most widely used form of attention in transformers is self-attention, where each token in a sequence attends to all other tokens, capturing long-range dependencies. This mechanism is further enhanced by multi-head attention, which enables the model to focus on multiple aspects of the data simultaneously.
There are several types of attention mechanisms, including self-attention, which is used in transformers to relate different words in the same sentence, and cross-attention, which is commonly seen in tasks like machine translation where the model attends to a separate input sequence.
In the video, I have visually explained each of these attention mechanisms with clear animations and step-by-step breakdowns.
Timestamps:
0:00 - Embedding and Attention
2:12 - Self Attention Mechanism
10:52 - Causal Self Attention
14:12 - Multi Head Attention
16:50 - Attention in Transformer Architecture
17:54 - GPT-2 Model
21:30 - Outro
Attention is all you need paper: https://arxiv.org/abs/1706.03762
Music by Vincent Rubinetti
Download the music on Bandcamp:
https://vincerubinetti.bandcamp.com
Stream the music on Spotify:
https://open.spotify.com/artist/2SRhEEt2tlDQWxzwfUo9Dl

 26:10
26:10
 19:33
19:33
![How DeepSeek Rewrote the Transformer [MLA]](https://i.ytimg.com/vi/0VLAoVGf_74/mqdefault.jpg) 18:09
18:09
 16:04
16:04
 1:52:27
1:52:27
 58:04
58:04
 22:02
22:02
 1:27:05
1:27:05
 3:08:16
3:08:16
 23:44
23:44
 8:55
8:55
 18:08
18:08
 49:53
49:53
 27:14
27:14
 57:45
57:45
 22:43
22:43
 20:18
20:18
 10:09
10:09
 44:26
44:26
 1:56:20
1:56:20





