
 45:43
45:43
 31:04
31:04
 12:16
12:16
 11:33
11:33
 27:38
27:38
 22:31
22:31
 30:31
30:31
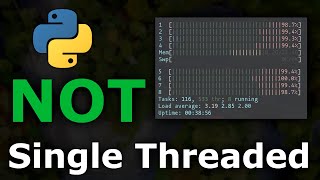 10:23
10:23
 20:33
20:33
 18:07
18:07
 18:46
18:46
 18:40
18:40
 25:28
25:28
 28:44
28:44
 30:38
30:38
 15:19
15:19
 27:59
27:59
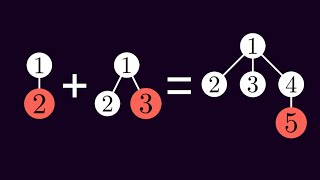 29:42
29:42
 1:00:03
1:00:03
 48:51
48:51





