ETL | Dynamic Incremental Data Loading from Amazon S3 Bucket to Amazon Redshift Using AWS Glue | AWS
===================================================================
1. SUBSCRIBE FOR MORE LEARNING :
https://www.youtube.com/channel/UCv9MUffHWyo2GgLIDLVu0KQ
===================================================================
2. CLOUD QUICK LABS - CHANNEL MEMBERSHIP FOR MORE BENEFITS :
https://www.youtube.com/channel/UCv9MUffHWyo2GgLIDLVu0KQ/join
===================================================================
3. BUY ME A COFFEE AS A TOKEN OF APPRECIATION :
https://www.buymeacoffee.com/cloudquicklabs
===================================================================
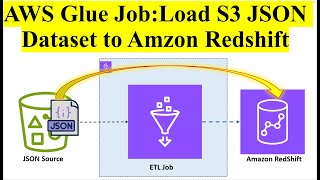
This video demonstrates how to dynamically load data from an Amazon S3 bucket into an Amazon Redshift cluster using AWS Glue, without relying on AWS Glue Crawlers. Instead, we use a custom script to manage schema definitions and data transformations, making this approach ideal for scenarios where flexibility and precision are required.
What You'll Learn in This Video:
Overview of AWS Services:
Learn the roles of Amazon S3 for scalable storage, Amazon Redshift for analytics, and AWS Glue for serverless ETL.
Setting Up Resources:
Configuring an Amazon Redshift cluster with appropriate security groups and IAM roles.
Creating an Amazon S3 bucket to store raw data files.
Preparing and uploading sample datasets.
Customizing AWS Glue Without Crawlers:
Writing a Glue ETL script in Python to directly define data schemas.
Using the AWS Glue dynamic frame API to transform and load data.
Managing schema evolution and handling data types programmatically.
Data Pipeline Execution:
Running the Glue job directly from the AWS Management Console.
Monitoring and troubleshooting job execution logs.
Validating the Data in Redshift:
Querying Redshift tables to ensure the data was loaded correctly.
Verifying data transformations and schema mapping.
Performance Optimization Tips:
Strategies for large-scale data processing without crawlers.
Optimizing Glue job execution times and Redshift cluster usage.
Use Cases Covered:
Loading data dynamically when crawlers are not suitable.
Handling custom schema definitions for specific data pipelines.
Automating S3-to-Redshift data workflows efficiently.
Who Should Watch This Video?
AWS developers and engineers who prefer scripting over automated tools like Crawlers.
Data professionals seeking advanced ETL techniques in AWS Glue.
Beginners looking for hands-on, practical guidance in AWS Glue and Redshift.
Resources Provided:
Sample Glue script: https://github.com/RekhuGopal/PythonHacks/tree/main/AWS_ETL_Increamental_Load_S3_to_RedShift_2
Sample dataset for testing: https://github.com/RekhuGopal/PythonHacks/tree/main/AWS_ETL_Increamental_Load_S3_to_RedShift_2
AWS Documentation:
AWS Glue
Amazon Redshift
Call to Action:
Don’t forget to like this video and subscribe to @cloudquicklabs for more in-depth tutorials on AWS and cloud technologies. Hit the notification bell so you never miss an update!
#etl #aws #awsglue #amazonredshift #s3toRedshift #dynamicloading #incrementaldata #datapipeline #bigdata #cloudcomputing #serverless #dataengineering #awsservices #redshiftetl #s3bucket #dataanalytics #clouddata #dataintegration #etlprocess #datasolutions #datatransformation #amazonwebservices #awsautomation #awstutorial #cloudtutorial #awsdataengineering

 13:51
13:51
 1:22:18
1:22:18
![AWS re:Invent 2024 - [NEW LAUNCH] Store tabular data at scale with Amazon S3 Tables (STG367-NEW)](https://i.ytimg.com/vi/1U7yX4HTLCI/mqdefault.jpg) 42:52
42:52
![AWS Glue Tutorial for Beginners [NEW 2024 - FULL COURSE]](https://i.ytimg.com/vi/ZvJSaioPYyo/mqdefault.jpg) 53:03
53:03
 2:09:21
2:09:21
 24:09
24:09
 25:19
25:19
 3:21:46
3:21:46
![AWS re:Invent 2024 - [NEW LAUNCH] Amazon SageMaker Lakehouse: Accelerate analytics & AI (ANT354-NEW)](https://i.ytimg.com/vi/LkH6ZzzA9dM/mqdefault.jpg) 51:10
51:10
 27:18
27:18
 24:59
24:59
 40:14
40:14
![AWS Glue for ETL (Extract, Transform, Load) + S3, RDS and Redshift [FULL TUTORIAL]](https://i.ytimg.com/vi/rVrTiJRTviA/mqdefault.jpg) 1:15:11
1:15:11
 1:56:28
1:56:28
 1:17:35
1:17:35
![AWS Glue Tutorial for Beginners [FULL COURSE in 45 mins]](https://i.ytimg.com/vi/dQnRP6X8QAU/mqdefault.jpg) 41:30
41:30
 1:33:52
1:33:52
 1:11:00
1:11:00
 22:02
22:02
 38:28
38:28





