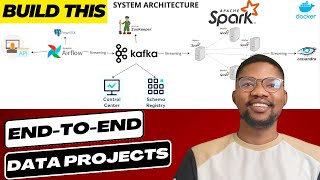
Ever wondered how to monitor a system that processes 1 billion records per hour seamlessly? In this video, we break down the architecture and tools to make it happen:
PART 2 AVAILABLE HERE:
https://youtu.be/PL6Tl2sqh8k
✅ Apache Kafka: The backbone of real-time data streaming.
✅ Apache Spark: Lightning-fast processing for massive data pipelines.
✅ ELK Stack: Gain visibility with Elasticsearch, Logstash, and Kibana.
✅ Grafana & Prometheus: Real-time monitoring and performance insights.
✅ Kafka Schema Registry & Control Center: Streamlined management and schema validation.
🎯 What You'll Learn:
✅ How to design a robust architecture for high-throughput data pipelines.
✅ Insights into Python vs. Java Kafka Producers: Which one performs better?
✅ Real-time logging, monitoring, and debugging strategies.
🔥 Why This Matters: If you're in data engineering or want to level up your skills, this video showcases everything you need to build, monitor, and scale an ultra-high-performance streaming platform.
Timestamps:
0:00 Introduction
3:33 Realtime monitoring with Prometheus
27:18 Outro
👀 Don't just watch it, build it! 🚧
👍 Like, Comment, & Subscribe for more cutting-edge data engineering content!
Resources:
Full Source Code:
https://buymeacoffee.com/yusuf.ganiyu/full-source-code-monitoring-high-performance-architecture-systems
Kafka Documentation: https://kafka.apache.org/documentation/
Apache Spark Documentation: https://spark.apache.org/documentation.html
JMX Exporter Agent - https://github.com/prometheus/jmx_exporter/releases
#ApacheKafka, #ApacheSpark, #DataEngineering, #BigData, #RealTimeProcessing, #ELKStack, #Grafana, #Prometheus, #KafkaStreams, #BigDataAnalytics, #DataPipeline, #StreamingData, #KafkaMonitoring, #SparkStreaming, #DataArchitecture, #HighPerformanceComputing

 20:08
20:08
 2:17:32
2:17:32
 4:51:14
4:51:14
 34:49
34:49
 3:03:43
3:03:43
 2:08:49
2:08:49
 1:25:26
1:25:26
 1:10:52
1:10:52
 1:27:48
1:27:48
 53:25
53:25
 1:11:00
1:11:00
 3:30:57
3:30:57
 1:15:10
1:15:10
 52:39
52:39
 3:01:19
3:01:19
 1:02:01
1:02:01
 36:21
36:21
 1:04:00
1:04:00
 21:27
21:27
 4:17:02
4:17:02





