PyData DC 2018
Most of your time is going to involve processing/cleaning/munging data. How do you know your data is clean? Sometimes you know what you need beforehand, but other times you don't. We'll cover the basics of looking at your data and getting started with the Pandas Python library, and then focus on how to "tidy" and reshape data. We'll finish with applying customized processing functions on our data.
===
www.pydata.org
PyData is an educational program of NumFOCUS, a 501(c)3 non-profit organization in the United States. PyData provides a forum for the international community of users and developers of data analysis tools to share ideas and learn from each other. The global PyData network promotes discussion of best practices, new approaches, and emerging technologies for data management, processing, analytics, and visualization. PyData communities approach data science using many languages, including (but not limited to) Python, Julia, and R.
PyData conferences aim to be accessible and community-driven, with novice to advanced level presentations. PyData tutorials and talks bring attendees the latest project features along with cutting-edge use cases.
0:00 Introduction
0:18 Setup: Github Repo, Jupyter Setup
5:35 Loading Datasets - panda.read_csv()
7:43 Dataset / Dataframe At A Glance
7:53 Get First Rows: df.head()
8:58 Get Columns: df.columns
9:15 Get Index: df.index
9:37 Get Body: df.values
10:46 Get Shape: df.shape
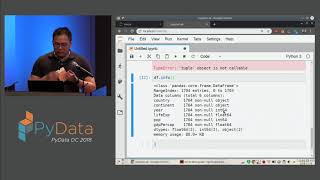
12:04 Get Summarizing Statistics: df.info()
13:12 Filtering, Slicing a Dataset / Dataframe
13:25 Extract a Single Column: df['col_name']
14:12 Dataframe vs Series
14:41 Extract N Columns: df[['col1_name', 'col2_name']]
15:51 Panda's Version: df.version
16:26 Extract Rows: df.iloc
17:30 Extract Rows: df.loc vs df.iloc vs df.idx
18:45 Extract Rows: df.iloc
19:37 Extract Rows: df.ix - Deprecated
20:38 Extract Multiple Rows and Columns
22:00 Extract Rows using Boolean Subsetting
23:24 Extract Rows using Multiple Boolean Subsetting
24:55 Cleaning a Dataset / Dataframe
25:38 General Issues according to a "Tidy Data" Research Paper
29:45 Issue 1: Column Headers are Values and not Variables Names
30:19 Load Pew Dataset
32:55 Transform Columns into Rows: pd.melt()
36:59 Load Billboard Dataset
37:05 Transform Columns into Rows: pd.melt()
42:00 Issue 2: Multiple Variables are Stored in 1 Column
43:06 Load Ebola Dataset
46:22 Transform Columns into Rows: pd.melt()
47:14 Split Column using String Manipulation through Accessors
51:19 Extract Column / Series from Accessor Split: accessor.get()
53:13 Add Column to Dataframe
54:13 Contracted Form for pd.melt() and Accessor String Manipulation: pd.merge()
56:10 Issue 3: Variables Stored in Rows And Columns
56:25 Load Weather Dataset
58:30 Transform Columns into Rows: pd.melt()
1:1:00 Transform Rows into Columns
1:2:00 Transform Rows into Columns: pd.pivot() vs pd.pivot_table()
1:4:30 Transform Rows into Columns: pd.pivot_table()
1:6:19 Flatten nested / hierarchical table: pd.reset_index()
1:7:42 Issue 4: Multiple Types of Observational Unit in Same Table (i.e De-nomalized Table)
1:9:43 Extract Type Observational Unit in new Dataframe, Drop Duplicates
1:11:30 Create "key" for extracted observational unit dataframe
1:12:11 Save new dataframe: pd.to_csv()
1:13:22 Merge / Join dataframe on common columns
1:16:25 Randomly Sample a dataframe
1:17:15 Note on Memory Consumption between all 3 dataframes
01:18:25 Summary from "Tidy Data" Research Paper
01:20:06 Q&A
01:21:21 Q&A 1: Simulating R's Chaining in Python
01:24:49 Q&A 2: Best Practices on Braquet Notation vs Chaining
Huge s/o to https://github.com/KMurphs for the video timestamps!
Want to help add timestamps to our YouTube videos to help with discoverability? Find out more here: https://github.com/numfocus/YouTubeVideoTimestamps

 30:04
30:04
 1:29:00
1:29:00
 1:54:11
1:54:11
 3:18:53
3:18:53
 38:37
38:37
 3:00:19
3:00:19
 43:32
43:32
 3:24:18
3:24:18
 27:38
27:38
 2:15:50
2:15:50
 1:11:58
1:11:58
 1:26:07
1:26:07
 1:17:14
1:17:14
 1:44:17
1:44:17
 11:30
11:30
 14:12
14:12
 3:45:17
3:45:17
 1:16:09
1:16:09
 3:59:04
3:59:04
 27:49
27:49