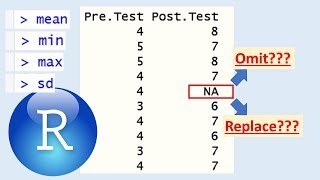
Calculating mean and other descriptives with missing values in R Studio
In this tutorial, I am going to show you how to calculate the mean and other descriptives (minimum, maximum, and standard deviation) in R studio, when having missing values in your dataset. Many pre- post-testing analyses will not properly run with missing values in your dataset. Therefore, it is important to consider what options or methods you may want to apply before analyzing your data.
The first part of this tutorial will involve omitting cases that have missing values (i.e., listwise deletion), before calculating the mean and other descriptives. This method provides us with a “complete cases” dataset, that is ideal for most analyses you may want to conduct for pre- post-testing. And the second part of this tutorial will involve adding values to missing values (i.e., mean substitution) before calculating the mean and other descriptives. This method provides us with a “manipulated cases” dataset, which could be useful, but should always be compared with the “complete cases” dataset as well.
Below is all the R code I used in this video. Please note that angle brackets are not allowed in youtube video descriptions, so I left notes below where the angle brackets need to be inserted within the code.
### Tutorial - Calculating mean and other descriptives with missing values in R
# Upload dataset
Data1 (insert angled bracket here)- read.csv(file.choose())
# Let's calculate the means and other descriptives for pre-test and post-test
# Descriptives pre-test
mean(Data1$Pre.Test)
min(Data1$Pre.Test)
max(Data1$Pre.Test)
sd(Data1$Pre.Test)
# Descriptives post-test
mean(Data1$Post.Test)
min(Data1$Post.Test)
max(Data1$Post.Test)
sd(Data1$Post.Test)
##############################################
### PART 1: Omit cases with missing values ###
# Re-run descriptives post-test!
mean(Data1$Post.Test, na.rm =TRUE)
min(Data1$Post.Test, na.rm =TRUE)
max(Data1$Post.Test, na.rm =TRUE)
sd(Data1$Post.Test, na.rm =TRUE)
# Or another method to do is...
# create a new dataset without any missing values included (listwise deletion)
Data2 (insert angled bracket here)- na.omit(Data1)
# Check Data 2
Data2
# Lets compare results of a paired-samples t-test on Data1 and on Data2
# Paired-samples t-test on Data1 (with missing values)
t.test(Data1$Pre.Test,Data1$Post.Test,paired=TRUE)
# Paired-samplpes t-test on Data2 (with no missing values)
t.test(Data2$Pre.Test,Data2$Post.Test,paired=TRUE)
# NOTE: No difference between the two tests. Cases were already omitted regardless if listwise deletion took place.
##############################################################
### PART 2: Replace cases with missing values with a value ###
# create a new dataset where missing values are substituted with a mean (mean substitution)
library(gam)
Data3 (insert angled bracket here)- na.gam.replace(Data1)
# Check Data 3
Data3
# Lets compare results of a paired-samples t-test on Data1 and on Data3
# Paired-samples t-test on Data1 (with missing values)
t.test(Data1$Pre.Test,Data1$Post.Test,paired=TRUE)
# Paired-samples t-test on Data3 (with mean substitution)
t.test(Data3$Pre.Test,Data3$Post.Test,paired=TRUE)
# NOTE: There is some minor differences between the two tests. Mean substitution can be used, but it has the possibility to alter the results as well.
# Good rule... is to always compare your results to a "completed cases" dataset where no manipulation to the dataset took place.
# So in this case, Data2 would be our "completed cases" dataset.
 15:41
15:41
 16:06
16:06
 17:17
17:17
 22:23
22:23
 22:47
22:47
 4:00:37
4:00:37
 11:56
11:56
 1:12:44
1:12:44
 7:47:08
7:47:08
 6:19
6:19
 22:49
22:49
 23:59
23:59
 9:08
9:08
 22:51
22:51
 21:55
21:55
 11:49
11:49
 19:44
19:44
 13:54
13:54
 18:36
18:36
 28:15
28:15





