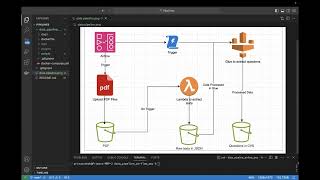
In this video, how to create a fully automated data cataloging and ETL pipeline to transform your data is explained in-depth from scratch.
Prerequisite:
-----------------------
Implement a CloudWatch Events Rule That Calls an AWS Lambda Function
https://youtu.be/2cLwSTsBzJQ
Using AWS Lambda with Amazon CloudWatch Events | Send notification when ec2 stops
https://youtu.be/WDBD3JmpLqs
Pipeline design with monitoring and alert functionalities using Cloudwatch Alarm , EC2 & Lambda
https://youtu.be/HW7XytRbJ84
Enable CloudWatch logs for API Gateway | Monitoring and Logging API Activity
https://youtu.be/B6wk5ErNClc
Invoking State Machine with CloudWatch
https://youtu.be/22yRNLm6BbQ
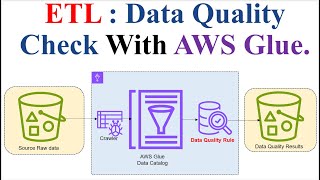
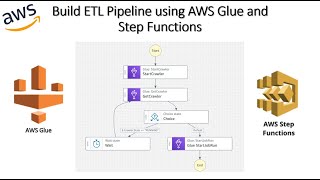
AWS Glue Workflow in-depth intuition with Lab
https://youtu.be/KC9t2yEyVSE
An automated data pipeline using Lambda, S3 and Glue - Big Data with Cloud Computing
https://youtu.be/1tIM1jBmwD4
Lambda Code to trigger Glue Crawler:
---------------------------------------------------------------
import json
import boto3
glue=boto3.client('glue');
def lambda_handler(event, context):
# TODO implement
response = glue.start_crawler(
Name='{Put the Name of the Glue Crawler here}'
)
return {
'statusCode': 200,
'body': json.dumps('Hello from Lambda!')
}
Lambda Code to trigger Glue Job:
----------------------------------------------------------
import json
import boto3
def lambda_handler(event, context):
glue=boto3.client('glue');
response = glue.start_job_run(JobName = "{Put the Glue ETL Job name here}")
print("Lambda Invoke")
Glue Code:
---------------------
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
## @params: [JOB_NAME]
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
datasource0 = glueContext.create_dynamic_frame.from_catalog(database = "{}", table_name = "{}", transformation_ctx = "datasource0")
datasink4 = glueContext.write_dynamic_frame.from_options(frame = datasource0, connection_type = "s3",
connection_options = {"path": "s3://{}/{}/"}, format = "parquet", transformation_ctx = "datasink4")
job.commit()
Cloudwatch rule for trigger the Lambda on success of the Glue Crawler:
-----------------------------------------------------------------------------------------------------------------------
{
"source": [
"aws.glue"
],
"detail-type": [
"Glue Crawler State Change"
],
"detail": {
"state": [
"Succeeded"
],
"crawlerName": [
"{Put your Crawler Name here}"
]
}
}
Cloudwatch rule for Triggering the SNS on success of Glue Job:
---------------------------------------------------------------------------------------------------------
{
"source": [
"aws.glue"
],
"detail-type": [
"Glue Job State Change"
],
"detail": {
"jobName": [
"{Put your Job name here}"
],
"state": [
"SUCCEEDED"
]
}
}
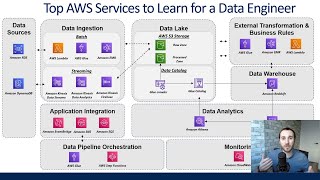
Check this playlist for more AWS Projects in Big Data domain:
https://youtube.com/playlist?list=PLjfRmoYoxpNopPjdACgS5XTfdjyBcuGku

 8:45
8:45
 1:26:44
1:26:44
![PySpark For AWS Glue Tutorial [FULL COURSE in 100min]](https://i.ytimg.com/vi/DICsZiwuHJo/mqdefault.jpg) 1:36:49
1:36:49
 15:56
15:56
 46:04
46:04
 37:19
37:19
 42:07
42:07
 30:43
30:43
 23:01
23:01
 35:33
35:33
 23:55
23:55
 19:36
19:36
 18:01
18:01
 13:11
13:11
 22:35
22:35
 18:15
18:15
 21:40
21:40
 29:10
29:10
 29:31
29:31
 26:39
26:39





