𝐓𝐨 𝐞𝐧𝐡𝐚𝐧𝐜𝐞 𝐲𝐨𝐮𝐫 𝐜𝐚𝐫𝐞𝐞𝐫 𝐚𝐬 𝐚 𝐂𝐥𝐨𝐮𝐝 𝐃𝐚𝐭𝐚 𝐄𝐧𝐠𝐢𝐧𝐞𝐞𝐫, 𝐂𝐡𝐞𝐜𝐤 https://trendytech.in/?src=youtube&sub=mockdec for curated courses developed by me.
I have trained over 20,000+ professionals in the field of Data Engineering in the last 5 years.
𝐖𝐚𝐧𝐭 𝐭𝐨 𝐌𝐚𝐬𝐭𝐞𝐫 𝐒𝐐𝐋? 𝐋𝐞𝐚𝐫𝐧 𝐒𝐐𝐋 𝐭𝐡𝐞 𝐫𝐢𝐠𝐡𝐭 𝐰𝐚𝐲 𝐭𝐡𝐫𝐨𝐮𝐠𝐡 𝐭𝐡𝐞 𝐦𝐨𝐬𝐭 𝐬𝐨𝐮𝐠𝐡𝐭 𝐚𝐟𝐭𝐞𝐫 𝐜𝐨𝐮𝐫𝐬𝐞 - 𝐒𝐐𝐋 𝐂𝐡𝐚𝐦𝐩𝐢𝐨𝐧𝐬 𝐏𝐫𝐨𝐠𝐫𝐚𝐦!
"𝐀 8 𝐰𝐞𝐞𝐤 𝐏𝐫𝐨𝐠𝐫𝐚𝐦 𝐝𝐞𝐬𝐢𝐠𝐧𝐞𝐝 𝐭𝐨 𝐡𝐞𝐥𝐩 𝐲𝐨𝐮 𝐜𝐫𝐚𝐜𝐤 𝐭𝐡𝐞 𝐢𝐧𝐭𝐞𝐫𝐯𝐢𝐞𝐰𝐬 𝐨𝐟 𝐭𝐨𝐩 𝐩𝐫𝐨𝐝𝐮𝐜𝐭 𝐛𝐚𝐬𝐞𝐝 𝐜𝐨𝐦𝐩𝐚𝐧𝐢𝐞𝐬 𝐛𝐲 𝐝𝐞𝐯𝐞𝐥𝐨𝐩𝐢𝐧𝐠 𝐚 𝐭𝐡𝐨𝐮𝐠𝐡𝐭 𝐩𝐫𝐨𝐜𝐞𝐬𝐬 𝐚𝐧𝐝 𝐚𝐧 𝐚𝐩𝐩𝐫𝐨𝐚𝐜𝐡 𝐭𝐨 𝐬𝐨𝐥𝐯𝐞 𝐚𝐧 𝐮𝐧𝐬𝐞𝐞𝐧 𝐏𝐫𝐨𝐛𝐥𝐞𝐦."
𝐇𝐞𝐫𝐞 𝐢𝐬 𝐡𝐨𝐰 𝐲𝐨𝐮 𝐜𝐚𝐧 𝐫𝐞𝐠𝐢𝐬𝐭𝐞𝐫 𝐟𝐨𝐫 𝐭𝐡𝐞 𝐏𝐫𝐨𝐠𝐫𝐚𝐦 -
𝐑𝐞𝐠𝐢𝐬𝐭𝐫𝐚𝐭𝐢𝐨𝐧 𝐋𝐢𝐧𝐤 (𝐂𝐨𝐮𝐫𝐬𝐞 𝐀𝐜𝐜𝐞𝐬𝐬 𝐟𝐫𝐨𝐦 𝐈𝐧𝐝𝐢𝐚) : https://rzp.io/l/SQLINR
𝐑𝐞𝐠𝐢𝐬𝐭𝐫𝐚𝐭𝐢𝐨𝐧 𝐋𝐢𝐧𝐤 (𝐂𝐨𝐮𝐫𝐬𝐞 𝐀𝐜𝐜𝐞𝐬𝐬 𝐟𝐫𝐨𝐦 𝐨𝐮𝐭𝐬𝐢𝐝𝐞 𝐈𝐧𝐝𝐢𝐚) : https://rzp.io/l/SQLUSD
30 INTERVIEWS IN 30 DAYS- BIG DATA INTERVIEW SERIES
This mock interview series is launched as a community initiative under Data Engineers Club aimed at aiding the community's growth and development
Our highly experienced guest interviewer, Satinder, https://www.linkedin.com/in/satinder-singh-699aab2b/ shares invaluable insights and practical advice coming from her extensive experience.
Our talented guest interviewee Aditya Patil, https://www.linkedin.com/in/ap-patil/ has an impressive approach to answering the interview questions in a very well articulated manner.
Link of Free SQL & Python series developed by me are given below -
SQL Playlist - https://www.youtube.com/playlist?list=PLtgiThe4j67rAoPmnCQmcgLS4iIc5ungg
Python Playlist - https://www.youtube.com/playlist?list=PLtgiThe4j67pQSwkaEF9uHXzr8Td9IEpV
Don't miss out - Subscribe to the channel for more such informative interviews and unlock the secrets to success in this thriving field!
Social Media Links :
LinkedIn - https://www.linkedin.com/in/bigdatabysumit/
Twitter - https://twitter.com/bigdatasumit
Instagram - https://www.instagram.com/bigdatabysumit/
Student Testimonials - https://trendytech.in/#testimonials
Discussed Questions : Timestamp
2:34 Brief overview of projects.
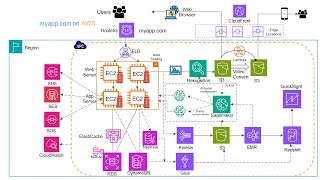
3:19 Describe your data pipeline flow and architecture.
5:10 What transformations do you use, and in which format do you write data to Redshift?
6:44 How do you handle null values?
9:03 Which file format do you use for end-user data?
9:50 Why is Parquet preferred over ORC?
11:10 What are the join types in Hive?
12:07 Which types of joins are used to avoid shuffling in Hive and PySpark? Do you know the specific term?
12:53 Explain how broadcast join avoids shuffling.
14:07 Which property controls broadcast join in Spark?
14:40 How do you start a Spark application in PySpark?
16:09 What does the builder do in Spark session creation?
17:43 What are the partitioning types in Hive?
18:36 Difference between managed and external tables in Hive.
19:16 Have you performed Spark performance tuning?
19:36 Difference between repartition and coalesce in Spark?
20:25 Have you used NoSQL databases?
21:02 SQL coding question
Tags
#mockinterview #bigdata #career #dataengineering #data #datascience #dataanalysis #productbasedcompanies #interviewquestions #apachespark #google #interview #faang #companies #amazon #walmart #flipkart #microsoft #azure #databricks #jobs

 1:02:07
1:02:07
 25:35
25:35
 41:32
41:32
 31:19
31:19
 31:45
31:45
 45:21
45:21
 1:00:00
1:00:00
 41:23
41:23
 46:07
46:07
 43:49
43:49
 41:04
41:04
 3:30:57
3:30:57
 22:29
22:29
 28:48
28:48
 50:59
50:59
 1:39:37
1:39:37
 47:48
47:48
 1:24:50
1:24:50
 37:23
37:23
 55:28
55:28





