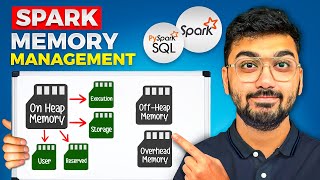
Welcome back to our comprehensive series on Apache Spark Performance Tuning/Optimisation! In this video, we dive deep into the intricacies of Spark's internal memory allocation and how it divides memory resources for optimal performance.
🔹 What you'll learn:
1. On-Heap Memory: Learn about the parts of memory where Spark stores data for computation (shuffling, joins, sorting, aggregation) and caching directly within the Java heap.
2. Off-Heap Memory: Discover how Spark utilises memory outside the Java heap to manage data storage in crucial situations.
3. Overhead: Understand the additional memory overhead required for managing Spark internals and how it impacts your applications.
4. Unified Memory: Explore the concept of unified memory management in Spark, the movable slider between execution and storage memory and the rules that define this movement.
5. Memory Calculation: How spark calculates and allocates memory to different storages.
📘 Resources:
📄 Complete Code on GitHub: https://github.com/afaqueahmad7117/spark-experiments
🎥 Full Spark Performance Tuning Playlist: https://www.youtube.com/playlist?list=PLWAuYt0wgRcLCtWzUxNg4BjnYlCZNEVth
🔗 LinkedIn: https://www.linkedin.com/in/afaque-ahmad-5a5847129/
📘 Chapters:
0:00 Intro
0:45 Roadmap
1:12 Executor Memory Layout
4:33 Executor Memory Calculations
11:52 Unified Memory
19:04 Off Heap Memory
22:30 Summary
#ApacheSparkTutorial #SparkPerformanceTuning #ApacheSparkPython #LearnApacheSpark #SparkInterviewQuestions #ApacheSparkCourse #PerformanceTuningInPySpark #ApacheSparkPerformanceOptimization #pyspark #databricks #dataengineering #interviewquestions #azuredataengineer